
(4-5 mins read)
Introduction & Recap
In the previous article, we explored transformers & the concept of attention, the driving force behind the effectiveness of large language models (LLMs) like ChatGPT, using a real-life analogy.
To recap, the attention mechanism helps models understand the context of input by focusing on specific parts and assigning weight scores to each word (or token). This process, known as the self-attention mechanism, evaluates the interaction between words based on their contextual relationships.
However, to capture the nuances of a sentence more comprehensively, the model needs to view the sentence from multiple perspectives simultaneously. And this is where multi-head attention comes into play.
Building on our previous understanding, let’s dive into the mathematical concepts behind attention matrices & introduce multi-head attention. This process can be complex, but I’ve simplified it as much as possible. So, brace yourself for a detailed exploration.
Recalling analogy & the summary flow

In the previous article, we saw how a group of 6 students with initial 7 characteristic parameters (represented by matrix [Q]), interacted with each other (represented by matrix [R]) & got transformed with new parameters (represented by matrix [T]). Let’s look at our analogy again step-by-step mathematically.
Step 1: The input matrix [Q] of 6 students, who are starting new phase in college, their characteristics are represented in form of below matrix:
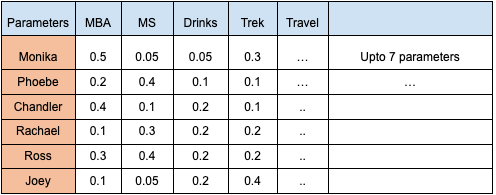
Table 1 Matrix [Q] (Values are random but depicts their interests towards different parameters)
Step 2: Now, these students interact with each other during their tenure & these interactions are being calculated, represented by matrix [R] (attention~interaction matrix):
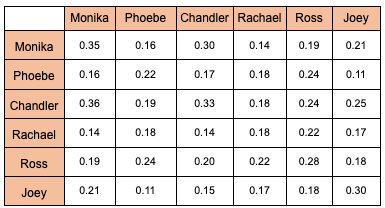
Table 2 Matrix [R]
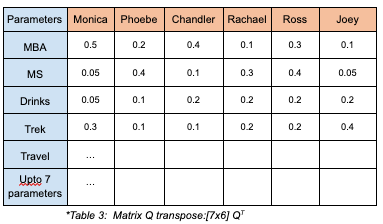
Mathematically, Table 2 is a result of dot product between matrix Q (table 1) & its transpose QT as given in table 3 below:
R or Attention score = Q x KT (where K = Q) ; This is a part of the Attention formula, as quoted in paper Attention is all you need, used to calculate attention score between any 2 words (or tokens in the world of LLMs).
So, as an example, let’s illustrate how to calculate the attention score (dot product) between Monica and Chandler using the values from tables 1 and 3:

The calculations will be w.r.t values from table 1 & 3 : 0.5 x 0.5 + 0.05 x 0.1 + 0.05 x 0.2 + 0.3 x 0.1 = 0.3
*Notice that whenever a dot product is calculated between matrix [axb] & [bxc], the new matrix will have dimensions [axc].
Step 3: After interactions, each individual will be transformed & hence their updated characteristics, as represented by a transformed matrix [T]
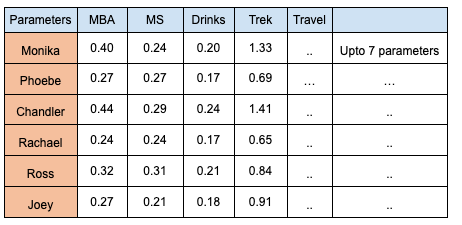
Table 4: Final Transformed matrix [T]
Mathematics behind above table:
To achieve the above matrix T in an efficient way, there are additional steps performed in matrix R & then multiply it with the original one Q. Please see below for details:
Step 3.a: We divide the Table 2 results by sq. root of no. of parameters of the original matrix i.e. 7 in this case, & do a softmax function, which is used to get the values for each row summation as 1 as shown below in the table 5, let’s call it matrix R’ [6 x 6 dimensions] :


Table 5 Matrix [R’]
Step 3.b: Final calculation to get the Transformed Matrix [T] (Table 4)
Table 4 is a result of dot product between matrix R’ with the original matrix Q to get the new scores for each individual based on their interaction scores i.e. the final formula would be as below:

which is part of the attention formula equation (where matrix Q = matrix V).
In the formula, the Q , K & V correspond to the same input matrix only but called Query, Key & Value.
Final Transformed Matrix [T] & the attention :
As explained earlier, the attention mechanism provides a way to weigh or “pay attention” to certain tokens (~input text) in a sequence more than others based on their relative importance or relevance to a given context, by assigning weights to each token-token interaction. Based on which, it helps the model to understand the sentence & also to predict the next output.
Therefore, if an input sentence comes like below & the model needs to predict the next word :
The bear eats the honey because he is ….??.
Vs
The bear eats the honey because it is …..??.
While our brain intuitively finds out who “he” is referred to vs “it”, the model has to perform an attention mechanism to understand it (by analysing the meaning of every word & interaction). And to predict the next word, it predicts the high probable word from its vocabulary:


Multi-head attention
We have seen previously how the model performs the attention process to understand each words’ interrelations. Now, what if a same word has different meanings or aspects in sentence, for example:
I enjoyed a crisp apple while scrolling through my favourite recipes on my apple.
While our brain intuitively finds out which apple I am talking about both the times, the model has to perform an attention mechanism in parallel to look into various aspects of all words which helps it to understand each word’s meaning, interrelations & hence the context, no matter how complex a sentence is.
This is achieved by the Multi-head attention mechanism & is used in all LLMs.
Multi-head attention through classroom students analogy
Let us go back to our classroom example of 6 students starting up a new phase in college.
Taking the case of Monica who wants to do MS in AI field. So, naturally her interaction would be more with someone who just is not interested to do MS but also into similar fields of her interest.

While interacting with each other, the following scenarios of students who wants to opt MS is found:
- 3 of those students who are interested in doing MS:
- 1 wants to do in Robotics Automation.
- 1 wants to do in Natural Language Processing
- 1 wants to do in Chemical Engineering
And naturally, while she finds out more specific interests by MS aspirants, she would form closer bonds with them. And this is what Multi-Head Attention does.
The Multi-Head Attention extends the concept of self-attention by employing multiple self-attention mechanisms in parallel. Instead of relying on a single perspective to understand the relationships between words, multi-head attention allows the model to consider various viewpoints simultaneously.
Summary
We’ve covered a long journey of understanding Self & Multi-Head Attention & saw how this core-technology plays a role to understand the input text & process it to accordingly predict the next output. And no matter how complex the input sentence is, the attention mechanism allows the model to simultaneously compute all elements in parallel, & give a precise or a better output.
If you want to understand this through video, you can visit this link on AI Pods youtube channel.
But all this process doesn’t just happen over the texts, rather it is converted to a computer understandable language called embedding & tokens which eventually also helps model for faster computing. In my upcoming articles, I will cover these concepts of Tokenization & Embedding.
Stay tuned!
References:
Transformers Explained – By Umar Jamil

Leave a comment