
Introduction & Why this article
We have learned previously how a Large Language Model (LLM) is able to understand any input sentence & produces outputs using attention mechanism.
However, the process is more complex than it appears. When LLMs encounter text, they don’t see words; they see numbers. Each word in a sentence is translated into a unique numerical identifier, which is mapped in the model’s vocabulary. For example: “Cat sits on the mat.” may appear as
| Cat | sits | on | the | mat | . |
| 245 | 1234 | 78 | 121 | 610 | 54 |
Given the countless languages & expanding vocabulary, it is technically not feasible for any model to incorporate every word in its vocabulary & assign a distinct number to each (see the next section example for clarity). And this is where tokenization steps in.
Introducing Tokenization in simple words
As Andrej Karpathy says, tokens are the fundamental building blocks of an LLM’s vocabulary & tokenization is the process of translating any input text into those sequences of tokens, each assigned a unique numerical ID.
For instance, consider the new word “Aipods,” the name of my recently launched blog, fed to the model. Instead of overwhelming it with an ever-growing list of words, tokenization splits “Aipods” into manageable pieces.
So, this might get split into following tokens depending upon the methodology being used. It could be split in either of the ways & accordingly a number ID will be assigned. See the table below (values are random)

On a similar note of handling any unfamiliar words or language, Tokenization holds immense significance in handling the complexities of various languages including new words, by segmenting the continuous strings of characters into meaningful units.
Tokenization methodology:
One widely used technique, including in models like ChatGPT, is Byte-Pair Encoding (BPE). It enables the merging of common pairs of characters, effectively reducing the vocabulary size.
You can refer to this blog post from Hugging face to understand how BPE works.
Unveiling Tokenization mathematically
Now, taking reference of Table 1 cat word, how does the model understand the token_id like 245 which is the representation of a token?
Recall from our previous discussions that in the world of LLMs, every input and output is akin to a matrix. This holds true for the tokenization process as well.
Let’s take the above sentence again “Cat sits on the mat.”
- Each word transforms into one/multiple tokens, represented by a unique number ID. For simplicity, let’s assume each word equals a token & is assigned the below token ID.
| Cat | sits | on | the | mat | . |
| 245 | 1234 | 78 | 121 | 610 | 54 |
- Mathematically, the values align in form of matrix [1,6] i.e.
| 245 | 1234 | 78 | 121 | 610 | 54 |
- Now, imagine a vocabulary comprising 10,000 tokens. Each token finds its place within a sprawling matrix, where its position signifies its identity. Technically, these tokens would be represented in below form where their corresponding position will be replaced by 1.
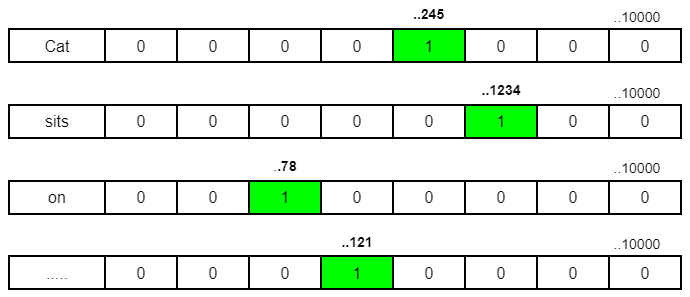
- Mathematically, the above sentence representation is in the form of a matrix of dimensions [6,10000] (where 10,000 is the model vocab size). And that’s how the model recognizes every token.
Summary & Impact on cost:
As demonstrated above, we saw how tokenization plays a pivotal role in making computations more feasible & transforming the way LLMs process and analyse data. As a rule of thumb, the number of tokens in a sentence typically hovers around 4/3 of the word count. Therefore, the judicious management of tokens mitigates costs: more tokens mean higher costs.
For example: I calculated the token count for English vs. Hindi for a similar sentence of four words in the ChatGPT 3.5 model. Following is the result:
I read books daily. Vs मैं रोज़ किताबें पढ़ता।
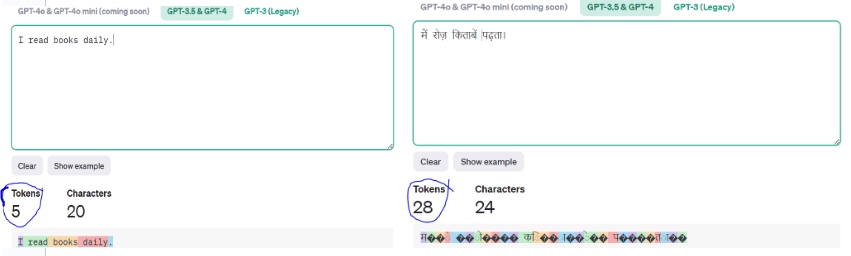
Since the ChatGPT3.5 model vocabulary is not well versed in hindi language, it splits every word into more units increasing the number of tokens and computation costs. In contrast, the model is more efficient with english, resulting in fewer tokens and lower costs. You can understand this with the image below.

What next?
So now, the model is able to identify the input text, converting it to token firstly & locating it in the existing vocabulary, but how to determine its meaning & properties to help the model understand the context. The answer lies in vector or embedding. And I will cover this into detail in my next article. Stay tuned!
References:
On Tokenizations in LLMs: By Mina Ghashami
Explained: The conspiracy to make AI seem harder than it is! By Gustav Söderström
https://huggingface.co/learn/nlp-course/en/chapter6/5
https://christophergs.com/blog/understanding-llm-tokenization

Leave a comment