
Introduction to Embedding
In the intricate realm of language understanding, each word has its own meaning, context, and nuance. To help AI models grasp these semantic meaning of the language, we use a technique called embedding.
The essence of Embedding:
Embedding is all about breaking down something into its essential features. And at the heart of it lies the concept of dimensionality. Imagine a red ball—if you want to fully understand it, you look at its color (red), shape (round), texture & so on. These are the ball’s key features. Same way, for a computer to understand a word (like “cat”), it needs to convert the word into a set of features. These features are represented within a multi-dimensional space.
For example, if we give 512 dimensions (as taken on master paper) to each word (token), we’re describing that word using 512 different characteristics. So, this can be represented or visualized as a [1 x 512] matrix for a single word. Now, if we have 10,000 words, it would be a [10,000 x 512] matrix:

Where, each token mapped in model vocabulary has been mapped in 512 dimensions.
So, the above input sentence “Cat sits on the mat” (consisting of 5 tokens) will get represented as below:

So, basically, every token of the sentence will have certain values corresponding to these 512 parameters. And the ones with similar property will stay close to each other.
Embedding concept through Real-life analogy example:
Let’s revisit our analogy from the previous article on Attention mechanism.
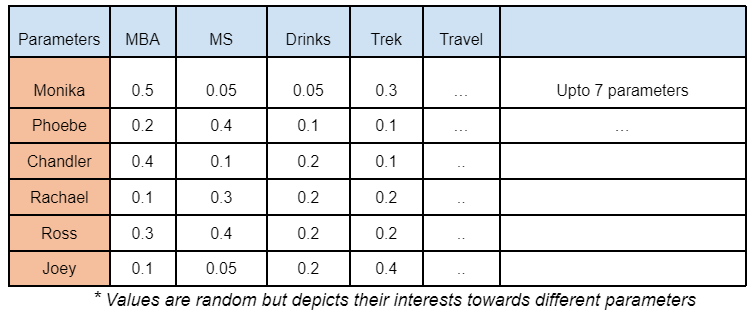
- Students ~ Tokens in the sentence
- 7 Parameters ~ 512 Parameters/features we call as dimensions
- Values assigned w.r.t student-properties ~ weight values
Earlier we’ve taken the total parameters of 7 as an example & represented (embedded) these 6 students corresponding to these parameters. In a similar way, any input tokens are represented or embedded in a high dimension of 512 parameters through a vector.
This process of representation of a word into a vector is called embedding. And in the realm of machine learning, every input & output format is represented in the form of a vector.
This is the language of an LLM. And this representation allows words of similar properties to stay in close proximity to each other.
Just like how we saw Monica’s case where she formed closer bonds with Chandler & Joey in relation to other students.

In vector space, this will look something like the below image where Monica, Chandler & Joey are closed to each other, while rest friends stay far away.

Of-course, there will be other combinations of students who would form closer bonds & thus stay close to each other. But due to space constraint & demonstrate you the embedding concept using one Monica’s case, the above image is showcased.
So, just like people of similar traits are closely positioned in the vector space, input tokens with similar properties will stay closed to each other.
Embedding & Training
Now, you might be wondering, how are these properties mapped for tokens. What decides the weight values that need to be assigned to any token?
Initially, the values within the embedding matrix called as weight matrix (recall matrix of 10,000 x 512) are randomly initialized, devoid of any inherent meaning. However, as the model undergoes rigorous training on vast datasets, it refines its understanding through a process of trial and error. With each incorrect output, the model adjusts its weight values through backpropagation, gradually honing its vocabulary to reflect the intricacies of language as shown in the image below

Summary:
In our exploration of tokenization & embedding, we’ve peeled back the layers of complexity surrounding AI language processing.
From the segmentation of text into tokens to the multidimensional representation of words, both tokenization & embeddings form powerful concepts that enable the AI models to capture the context & meaning of the text. While tokens provide a roadmap, embedding offers a compass, guiding the model through the intricate maze of language.
And of course, there is always an error chance, which model learns through human feedback (called Reinforced learning human feedback or RLHF).
Now, we have a powerful model trained on generic parameters. What if we want a customized model trained on a specific dataset? The answer lies in concepts of Retrieval Augmented Generation (or RAG) & Fine-tuning & we’ll cover one of these in the next article. Stay tuned !
References

Leave a comment